
Quality data is the bedrock of a high-functioning supply chain, with inconsistent or inaccurate data fueling overspending and underperformance. Unfortunately, most supply chain leaders are unaware that their data is creating a ripple effect throughout their networks.
You might think that data maturity would be a prerequisite for completing a supply chain network design, but this is not the case. In fact, network modelling can quickly reveal gaps in your data, allowing for assumptions to be made and a plan to be forged to close the gaps over time.
What is Supply Chain Data?
Data is what makes supply chains go ‘round. Your supply chain network is made up of massive amounts of data, quantifying every aspect of your operations. When completing a supply chain network design, you will need visibility into several categories of your data.
- Product: SKU or Item master data that define product attributes like dimensions, weight, quantities (cases, inners, pallets, etc.) as well as a hierarchy to properly aggregate relevant logistical groupings (receiving, handling, put-away, picking, packing and shipping)
- Supply: Data about suppliers, purchase orders/volumes, lead times, COGS.
- Demand: Historical sales volumes, customers’ physical locations and seasonality where applicable.
- Transportation: Mode of transportation, freight spend, freight terms, transit times, transportation lanes and the associated KPIs.
- Warehousing and Distribution: Facility locations, layouts, sizing, capacities, throughputs, fixed and variable operating costs and more.
- Inventory: Historical on-hand quantities over time, cycle and safety stock levels, holding costs and more.
- Costs: Within the previously mentioned datasets, having line of sight into the supply chain profit and loss will be the basis of comparison for future state optimisations.
This is just a snapshot of the type of data your supply chain network design will analyse. Your visibility—or lack thereof—into accurate numbers in each of these areas has far reaching impacts on the health of your supply chain.
The Importance of Supply Chain Data
The purpose of data in the supply chain is not just to have the numbers, but to use them to make strategic decisions that will improve your business outcomes.
For example, if your data shows that your on-time delivery rate is 60 percent, knowing other data like transit times, fulfillment rates and stockouts can reveal the contributing factors and enable you to work toward a solution.
What Causes Poor Quality Data?
It’s clear that quality supply chain data is critical, but gaps can still occur, especially without proper data governance across the organisation.
A few factors can lead to poor quality data across your supply chain network:
- Lack of accountability: Forecasting data comes from multiple sources. If every team is not adhering to the same processes for loading data into the necessary system, you can face issues like missing data and duplicate entries.
- Outdated information: Data is dynamic and needs constant monitoring. If you don’t have a system for regularly updating your data, it could be out of date, and you won’t even know it. This can lead to “noise” within your results.
- Manual processes: Businesses that use manual data entry processes often experience incorrect data due to human error.
- Lack of training: To achieve enterprise-level data quality and visibility, the entire organisation has to be trained on the what, why and how behind your data practices. Without this, processes will slip, and data quality will suffer.
- Inconsistent formats: Consistency is key when it comes to data. Having different formats for different datasets can create challenges down the road.
- Poor data governance: Ongoing data governance is just as important as initial data collection. Without it, your data, no matter how high quality it begins, will slowly erode over time.
- Errors during data migration: Migrating data to a new system is a common cause of data gaps for supply chains. Improper migration could lead to missing or disorganised data.
Signs of Poor Supply Chain Data
When collecting data for a supply chain network design, our consultants often find that the client doesn’t even realise the state of its data. Often, clients come to us with a very specific supply chain challenge, unaware that those challenges are being driven by gaps in their data.
Here are some signs that your data could use evaluating:
- You do not have a strategy for collecting, processing, or manipulating data.
- You rely on the tribal knowledge of a few individuals for accessing and aggregating data.
- You use manual data processes rather than automating with BI tools.
- You do not have a data management plan for maintenance and regular audits.
- You have disparate data tools across departments.
- You have disparate data storage across systems, like multiple ERP or WMS instances.
- You have restricted back-end access and front-end manipulation of your data.
- Your master data maintenance is cumbersome or not properly managed.
- Your decision makers lack trust in your data and do not use it when making key decisions.
Overcoming Poor Data with a Supply Chain Network Design
A supply chain network design can be a powerful catalyst for transforming poor data into actionable insights. Rather than waiting for perfect data, organisations can use the network design process as a data improvement initiative.
Here are some ways that a supply chain network design can help you overcome poor quality data:
The Iterative Data Improvement Approach
Supply chain network design projects follow an iterative methodology that naturally uncovers and addresses data gaps. The data collection phase identifies what data exists, what’s missing and what’s unreliable. This assessment becomes the foundation for both immediate modeling assumptions and long-term data improvement strategies.
Creating Intelligent Assumptions
When data gaps are identified, existing data trends, industry benchmarks and statistical methods can help create reasonable assumptions. For example:
- Depending on freight terms, transportation cost data is not always available. This can be estimated using distance-based models and industry rate structures.
- Missing item or SKU attributes can be assumed based on existing characteristic data from other SKUs with similar characteristics.
- Facility operating costs can be estimated using industry standards adjusted for local market conditions.
Building Data Collection Processes During Implementation
The network design process naturally creates opportunities to establish better data collection mechanisms. As you open facilities, establish new transportation lanes or redesign processes, you will be building proper data capture from day one. This will benefit your future network optimisations with higher quality information.
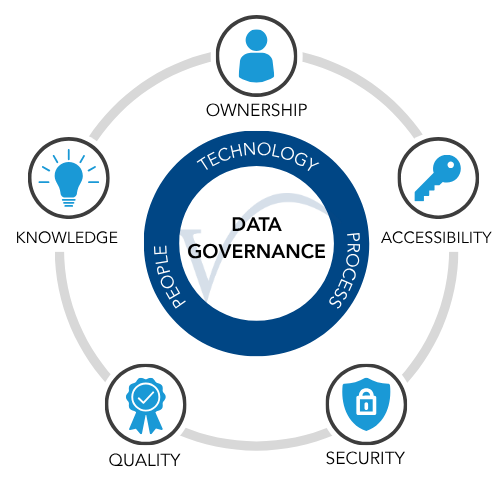
Establishing Data Governance Frameworks
A comprehensive supply chain network design includes recommendations for ongoing data governance, including data ownership, auditing processes, automated data validation rules and standardised formats. Data requirements uncovered during the modeling process can help establish these frameworks.
Change Management and Training
Successful data improvement requires organisational buy-in. The network design process can identify training needs, highlight the importance of data quality to frontline employees and create accountability structures that help sustain data governance practices over time.
Optimise Your Supply Chain Network with enVista
No matter the state of your data today, enVista’s proven methodology combines advanced analytics with deep industry expertise to design an optimised network that balances cost, service and risk while improving your data foundation for long-term success.
Are you ready to make your supply chain a competitive advantage? Let’s have a conversation.®



